今天,我們要來分享非監督式學習的另一種分群方式,DBSCAN。
什麼是DBSCAN?
DBSCAN的全名是Density-based spatial clustering of applications with noise。顧名思義,就是基於密度的分群方式。簡單來說,就是我們會將特徵相近且密度高的樣本劃分為一群,並標示出特徵較遠密度較稀疏的局外點,另做分群。
DBSCAN的運作方式
在DBSCAN中,有兩個主要的參數,分別為距離以及最少點數。
距離: $\epsilon$ (半徑) 最少點數: minPts
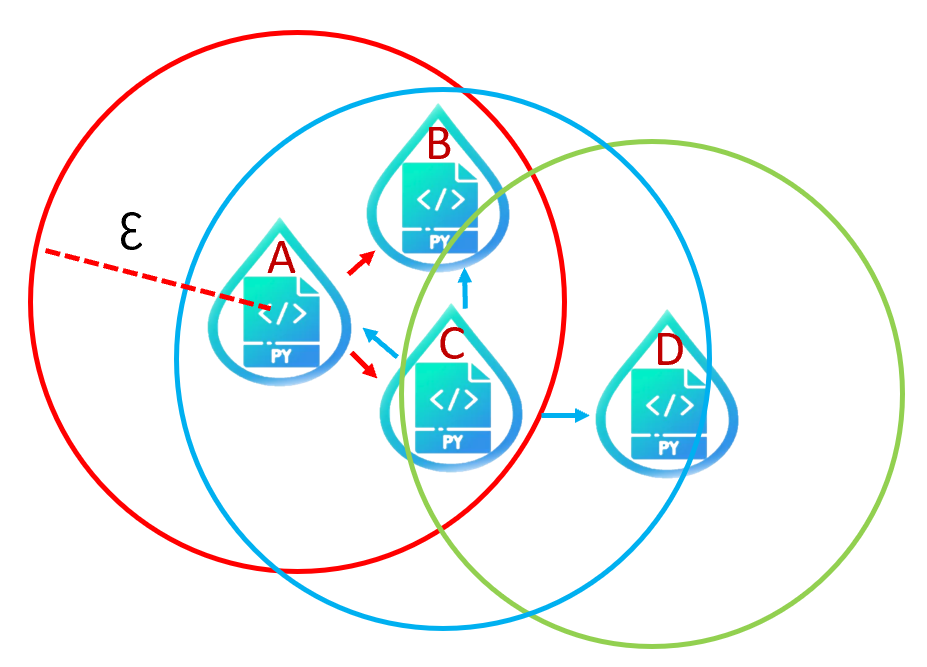
我們將樣本當圓心,以距離$\epsilon$為半徑畫圓,觀察圓內會包含多少樣本點。而最少點數為我們設定的門檻值,也就是說這個圓內需要至少包含的樣本數目。在此,假設我們設定最少點數為3,若圓內樣本數少於最少點數,則我們稱此中心點的樣本為非核心點(如上圖D),不論圓內有多少樣本點都不可達。反之,若樣本數大於等於最少點數,則此中心點的樣本為核心點(如上圖A,C),可到達圓內任何一點,我們稱之為可達性(單向箭頭)。若樣本與樣本之間為雙向可達,我們稱之為連結性(雙向箭頭)。 註: 其實B也是核心點,只是我們這邊並沒有把以B為圓心的圓畫出。
DBSCAN流程:
1.參數設定: 決定距離(半徑)$\epsilon$ 與 最少點數(門檻值) 2.任意選取一個樣本當作中心點,以步驟1設定好的半徑畫圓。 若圓內樣本數大於等於門檻值,則此一樣本為核心點,標記可達到圓內任一點。 若圓內樣本數小於門檻值,雖本身不可達,但被核心點可達,則稱之為邊界點。 若圓內樣本數小於門檻值,且不被核心點可達,則稱之為局外點(或雜訊)。 3. 對每一個樣本重複步驟2的動作,直至所有樣本都當過中心點為止。 4. 分群: 將有連結性(雙向可達)的樣本點劃分為一群,並納入單向可達的邊界點。其他局外點(雜訊)則劃分為另一群。
以下圖為例,我們設定半徑為$\epsilon$與最少點數為3,分別以A,B,C,D,E,F,G畫圓,計算圓內樣本是否達到最少點數後,會得到以下結果。 (詳細過程可參考影片)
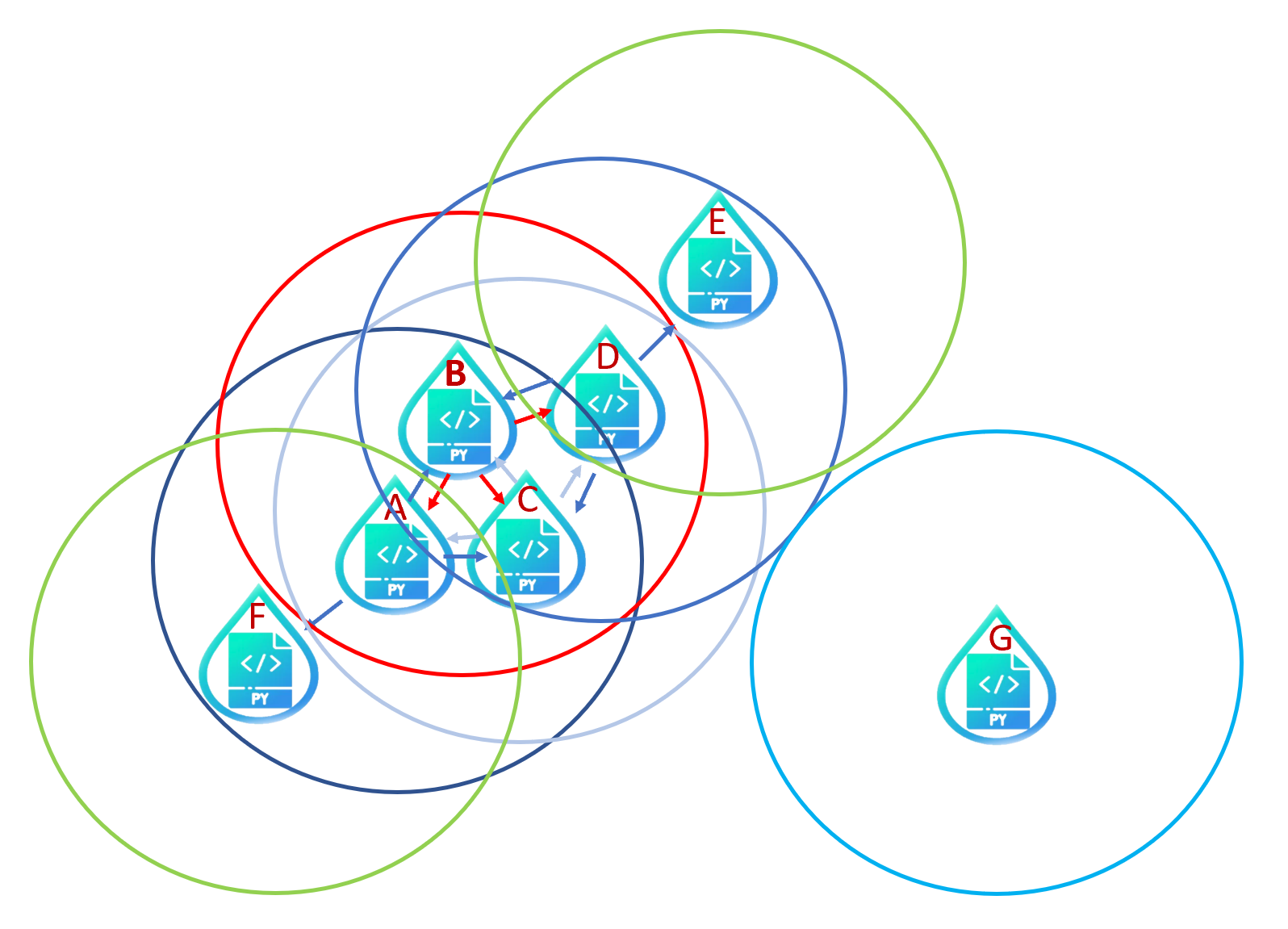
在圖中我們可以看到,ABCD之間互有雙向箭頭,也就是所謂的連結性。在A與D之間雖然沒有直接的連結性,但可透過BC兩點連結。因此,ABCD屬於同一群。而E與F雖然與中間ABCD樣本沒有連結,但同被這個群體可達,因此也屬於ABCD這群,所以說,這個紅色群包含了具有連結性(雙向可達)的核心點ABCD以及單向可達的邊界點E跟F。而G不被任何點可達也不可達到任何點,稱之為雜訊,因此自為一群。最後,就可以看到我們的分類如下圖。
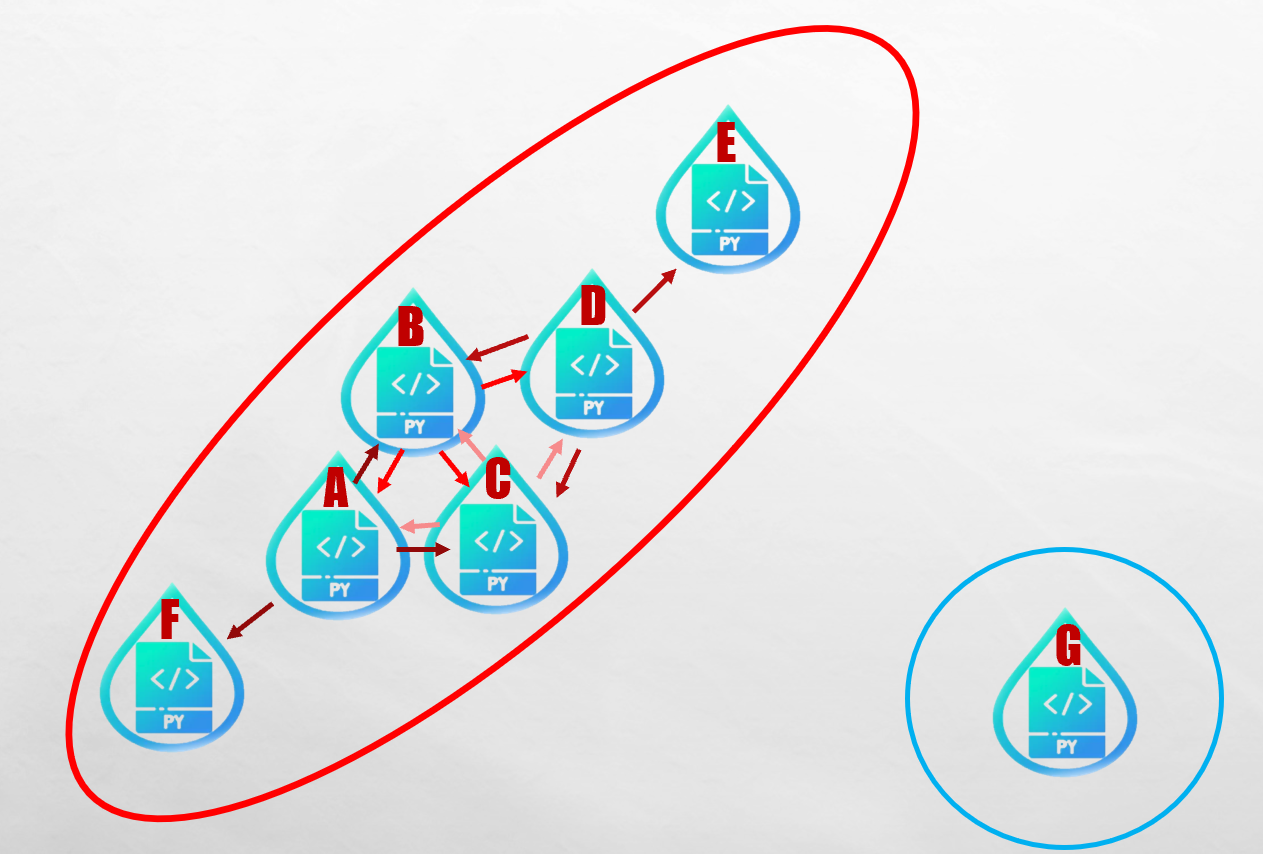
從結果我們也可以很明顯看到,這樣的分類方式完全符合DBSCAN這個名字,就是以密度來做分群。中間ABCDEF密度較高的為一群,而獨自在遠方的G,自為一群。
不同分群方式的特性
在scikit learn官網的視覺化圖中,我們可以明顯看到DBSCAN與我們先前分享的其他分群方法之差異。大部分的分群方式是直接以距離做分群的依據,DBSCAN則是依照密度來做分群依據,因此時常可以看到中心群外圍自成另一群的分類結果。讀者們可以依照自身的需求,選擇合適的分群方式。
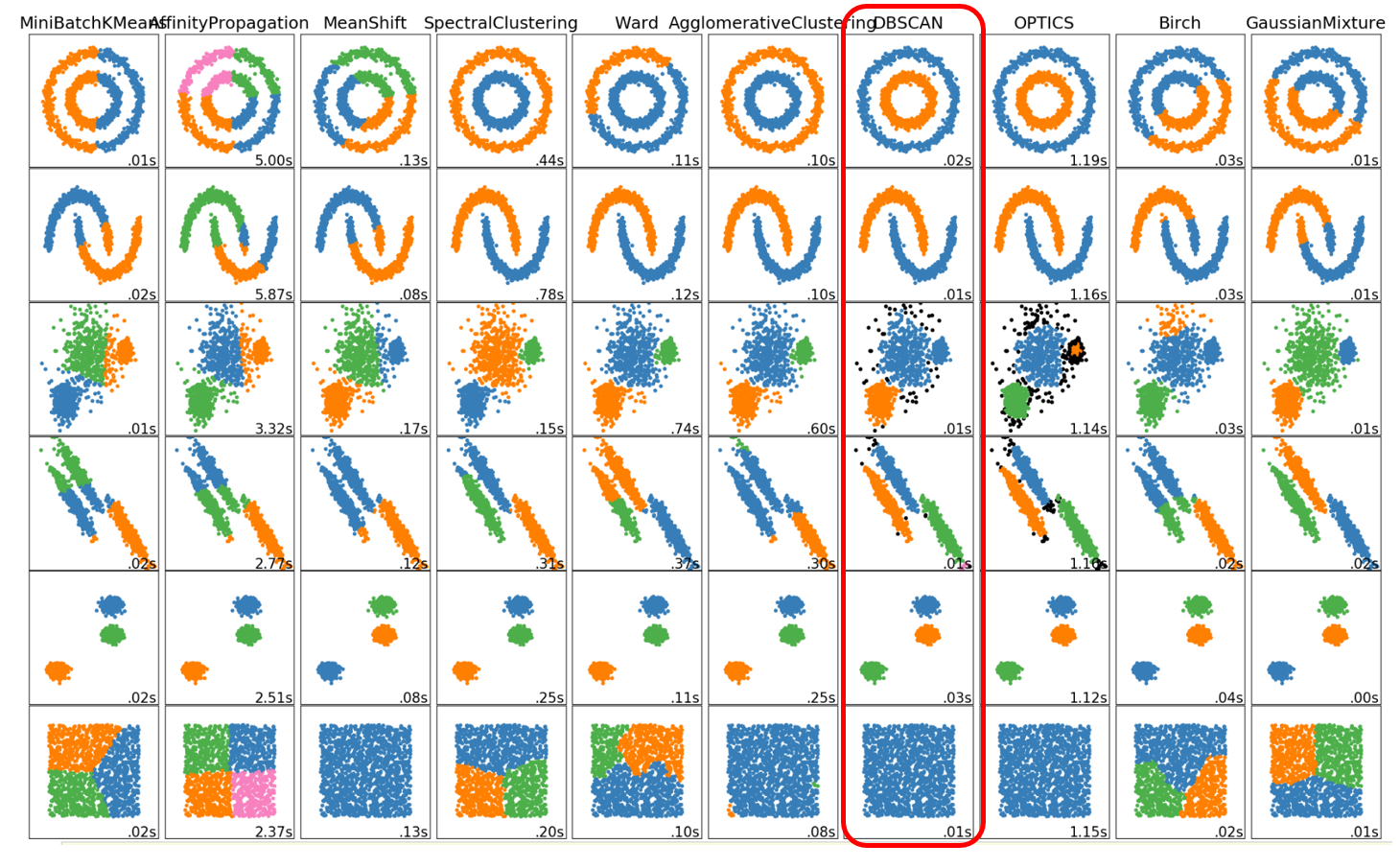
資料來源: scikit learn
DBSCAN的優缺點
DBSCAN主要的好處為: 1. 不受極端質影響。 因此方法基於密度分類,故極端值可自成一群。 2.不須事先選擇樣本群數,模型中會自動決定。
DBSCAN主要的缺點為: 1.維數災難。若維度過高,則須非常大量的樣本才能達到比較好的預測效果。 2.若資料密度差異大,效果會較差。
今天,我們認識了基於密度分群的非監督式學習,DBSCAN。下個單元,我們將一起用Python進行實作!