Hierarchical Clustering 為層次聚類的分群方式,屬於非監督式學習的一種。本單元透過大家所熟悉的鳶尾花資料集,看到在Python裡如何實作層次聚類。文末提供程式檔案,歡迎大家一起下載練習!
(一) 引入模組及準備資料
第一步,我們一樣會引入一些常用的運算及繪圖模組,還有scikit learn裡面所提供的鳶尾花資料及進行資料下載。
import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn import datasets
今天,為了視覺化,我們僅採用花瓣的長度及寬度當作我們的特徵資料。如果大家手邊有自己的資料,也非常鼓勵採用自己的資料進行實作唷!
iris=datasets.load_iris() X=iris.data X=X[:,2:4]
(二) Scikit Learn
今天,我們會分享兩種在python裡層次聚類的分群做法。一種是我們熟悉的scikit learn裡面的模組,另一種則是在scipy模組裡面。
首先我們先來看到sklearn裡面的作法,基本上就是我們所熟悉的機器學習建模流程。
1.引入層次聚類的模組
from sklearn.cluster import AgglomerativeClustering
2.進行分群
ml=AgglomerativeClustering(n_clusters=3,affinity='euclidean',linkage='ward')
其中, n_clusters: 要分成幾群 ,給定數值 affinity: 距離的計算方式,”euclidean”,”l1″,”l2″,”manhattan”,”cosine”… linkage: 群與群之間的距離,”ward”,”complete”,”average”,”single”
3.分群結果與圖像化顯示
進行預測:
ml.fit_predict(X)
圖像化顯示:
plt.scatter(X[:,0],X[:,1],c=ml.fit_predict(X))
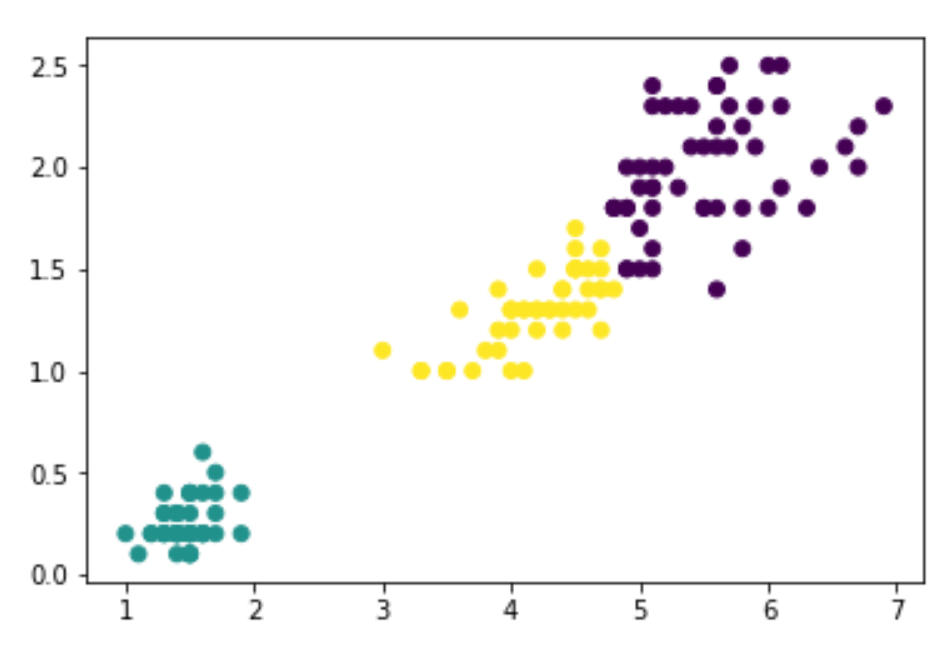
(三) Scipy
在scipy裡面,對於群與群之間距離的計算方式,提供了更多元的算法,除了single, complete, average, ward外,還包含了加權法、中心點法及中位數法等提供選擇。(其實sklearn裡面也可以做到這些,只是自己要另外將該演算法寫成函數)
1.引入層次聚類的模組
import scipy.cluster.hierarchy as sch
2.進行分群,並圖像化整個聚落樹狀圖
進行分群: dis=sch.linkage(X,metric='euclidean',method='ward')
其中, metric: 距離的計算方式 method: 群與群之間的計算方式,”single”, “complete”, “average”, “weighted”, “centroid”, “median”, “ward”
sch.dendrogram(dis) plt.title('Hierarchical Clustering') plt.show()
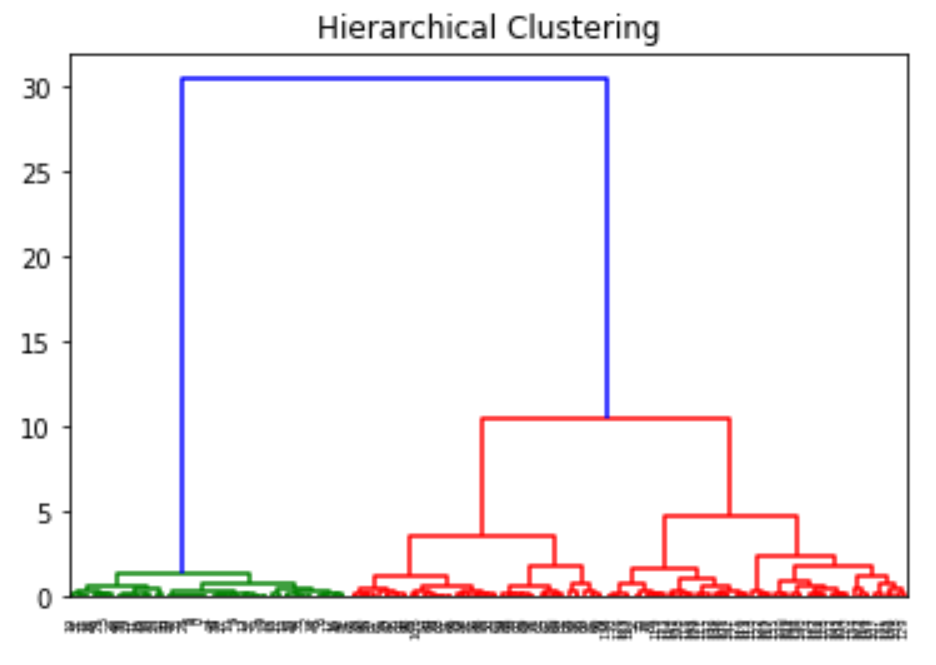
3.利用距離決定群數,或直接給定群數。
建構好聚落樹狀圖後,我們可以依照距離的切割來進行分類,也可以直接給定想要分類的群數,讓系統自動切割到相對應的距離。
A. 距離切割
上圖縱軸代表距離,我們可以用特徵之間的距離進行分群的切割。
max_dis=5 clusters=sch.fcluster(dis,max_dis,criterion='distance')
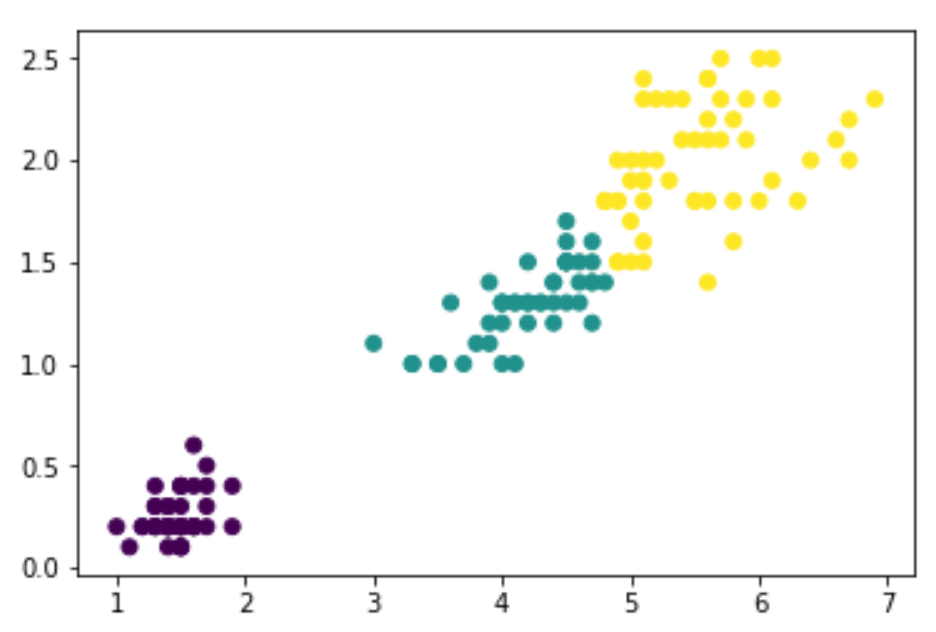
B.直接給定群數
同時,我們也可以像sklearn一樣,直接給定我們所想要分出的群數。
k=5 clusters=sch.fcluster(dis,k,criterion='maxclust')
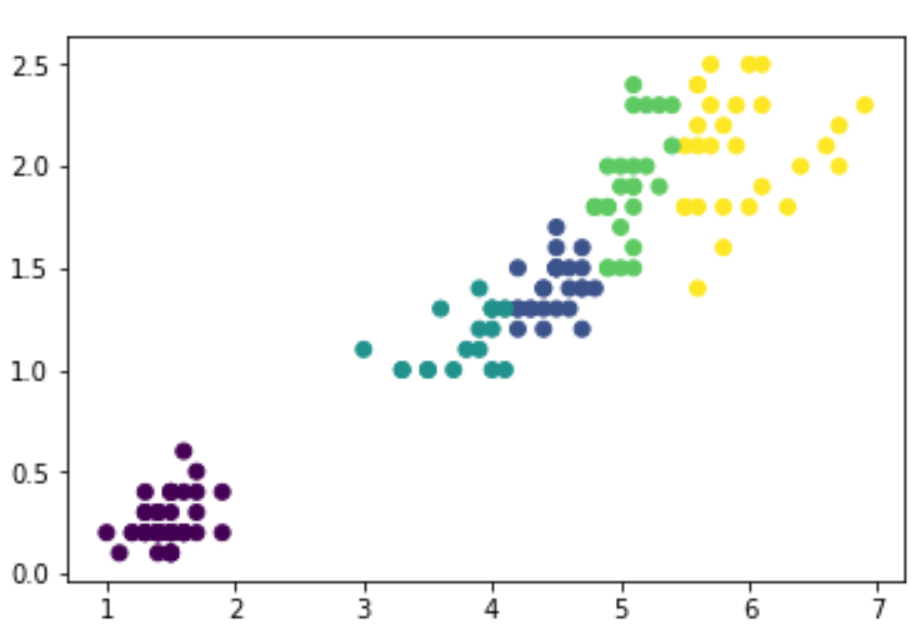
今天,我們在python裡實作Hierarchical Clustering的兩種方式。大家也可以運用這個方法,針對自己想要分析的資料分群看看唷!
程式檔案,歡迎於此下載。