今天,我們要來聊聊另一種聚類分析的分群方式,Hierarchical Clustering,層次聚類。層次聚類是屬於無標籤的非監督式學習,主要的概念為將所有樣本中相近得樣本點組成一個群組,一層一層往上堆疊,直至所有的樣本皆被分成一個群組為止。最後可透過距離的切割自由決定要分成多少群組。
Hierarchical Clustering 的運作原理
層次聚類的運作原理相當簡單,就是投過將最接近的樣本集成一群的方式,一層一層擴大群組,最後再決定想要分割成多少群組。主要流程可以分成以下幾個步驟:
步驟1: 計算樣本間個點的聚離 步驟2: 將距離最接近的合成一群,成為新的組合樣本點 步驟3: 重複步驟1及步驟2的步驟,直到所有樣本都成為一群為止 步驟4: 依照距離切割,決定最終聚類群數
詳細分群過程可參考影片中的例子。
聚類之間距離的計算方式
樣本點與樣本點之間的距離是很明確的,一般來說我們會用兩點之間最接近的距離,也就是歐基里德距離來做計算。當然,我們也可以依需求採用其他距離計算方式如曼哈頓距離或明氏距離等等。然而,當樣本點與樣本點合併成群組後,群組與群組之間的距離該怎麼計算呢?在計算群組與群組間的距離時,我們一樣可以依照自身需求來定義群組間的距離計算方式。在這裡我們提供以下幾種方式給大家參考:
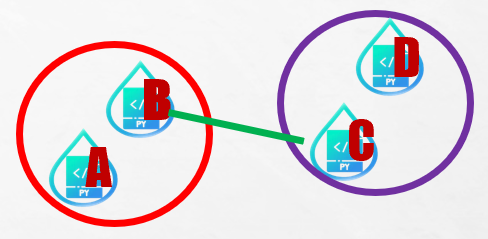
1. Single linkage
從兩群中分別選出讓兩群中距離最小的樣本點為代表,以此兩點之間的距離代表群體距離。
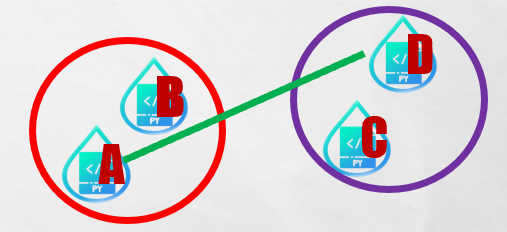
2. Maximum (Complete) linkage
從兩群中分別選出讓兩群中距離最遠的樣本點為代表,以此兩點之間的距離代表群體距離。
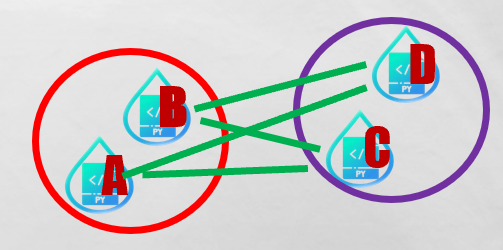
3. Average linkage
兩個群中所有樣本點之間的平均距離。
4. Ward 沃德法 (最小平方)
主要思想: 群內樣本的樣本距離平方和較小,群與群之間的樣本距離平方和較大 做法: 兩群合併後,檢視各樣本點與合併後的群中心距離平方和 (簡單來說,在群與群合併的過程中,會選擇讓距離平方和增加最小的兩群進行合併)
下圖為不同型態的樣本資料在不同的群與群距離計算方式下分類的結果:
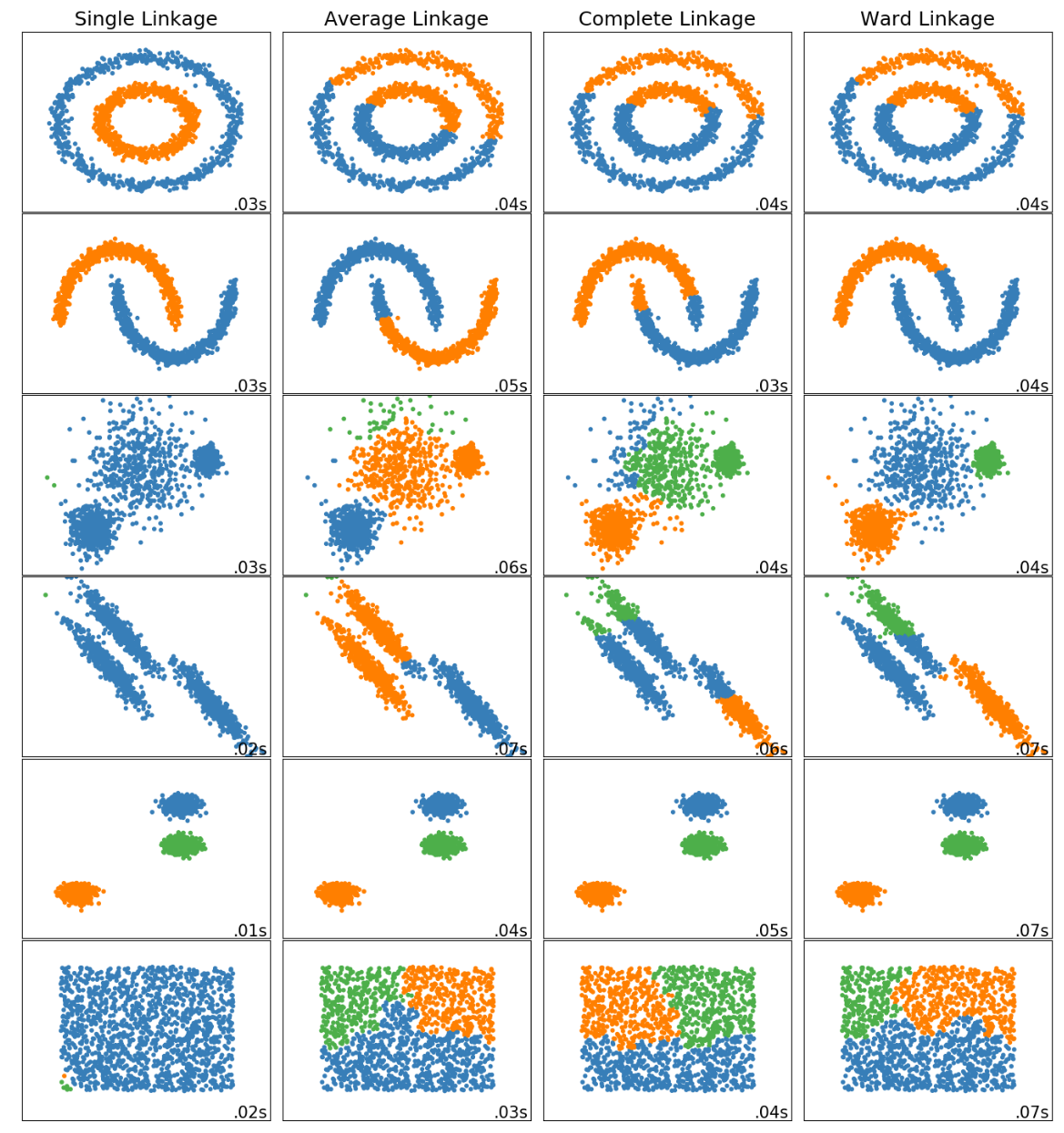
資料來源: scikit-learn
Heirarchical Clustering 的優缺點
層次聚類最大的優點就是他相當簡單易懂,而且當我們建構完整個完整的樹狀分類,我們可以很方便的決定想要分成幾群。另外,在這個分群架構下,我們不一定要有樣本的座標,即使我們只有樣本間的距離,也可以將分群這件事做得很好,所以它的彈性是很大的。
然而,從上述計算過程中,我們可以發現到,這個分群方法的計算量是非常龐大的。因此,這個方法僅適用於小樣本的資料。
今天,我們認識了層次聚類以及其背後的運作原理。下個單元,我們將用python一起進行實作!