認識了隨機森林模型之後,在這個單元,我們將帶大家在Python進行隨機森林模型的實作。為了維持一貫性,方便大家比較不同模型之間的差異,在這個單元,我們決定沿用決策樹模型單元的案例,一起用隨機森林模型來做鳶尾花的分類!
(一) 引入模組
首先,我們一樣從sklearn模組裡面引入前人已經完成的模型,在這邊我們引入的是隨機森林分類器。另外,我們也要引入資料集、區分訓練集資料與測試集資料模組,以及繪圖模組。
from sklearn.ensemble import RandomForestClassifier from sklearn import datasets from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt
(二) 模型建構
這邊的前置作業都與決策樹模型不相上下,唯有在步驟三模型選擇的部分我們這次選擇的是隨機森林模型。
Step1. 建立特徵X,與目標y Step2. 將資料區分成訓練集與測試集,可自行設定區分的百分比 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) Step3. 選擇隨機森林分類器,內容可決定決策數的棵樹、剪枝葉等等,以提升模型的效率及避免過度配適。 rfc=RandomForestClassifier(n_estimators=100,n_jobs = -1,random_state =50, min_samples_leaf = 10) Step4. 用建立好的模型來預測資料 rfc.predict(X_test) **Step5.**檢驗模型的正確率 rfc.score(X_test,y_test)
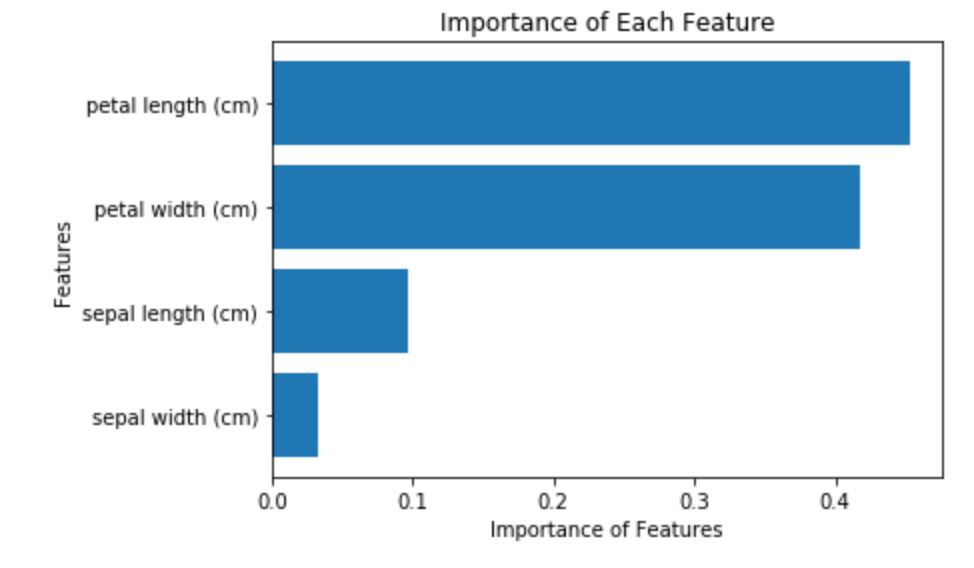
(三) 重要特徵
在這裡,我們也可以用featrue importance來評估各個特徵的重要程度,最後可以用繪圖視覺化顯現,範例如下。
imp=rfc.feature_importances_
詳細操作過程歡迎參考影片內容。 程式檔的部分可在此下載。