Ensemble Learning(集成學習)主要是透過結合多個機器學習器而成的大模型。在上個單元,我們介紹過了每個模型各自獨立的Bagging,這個單元,我們要來看會針對錯誤不斷訓練的Boosting!
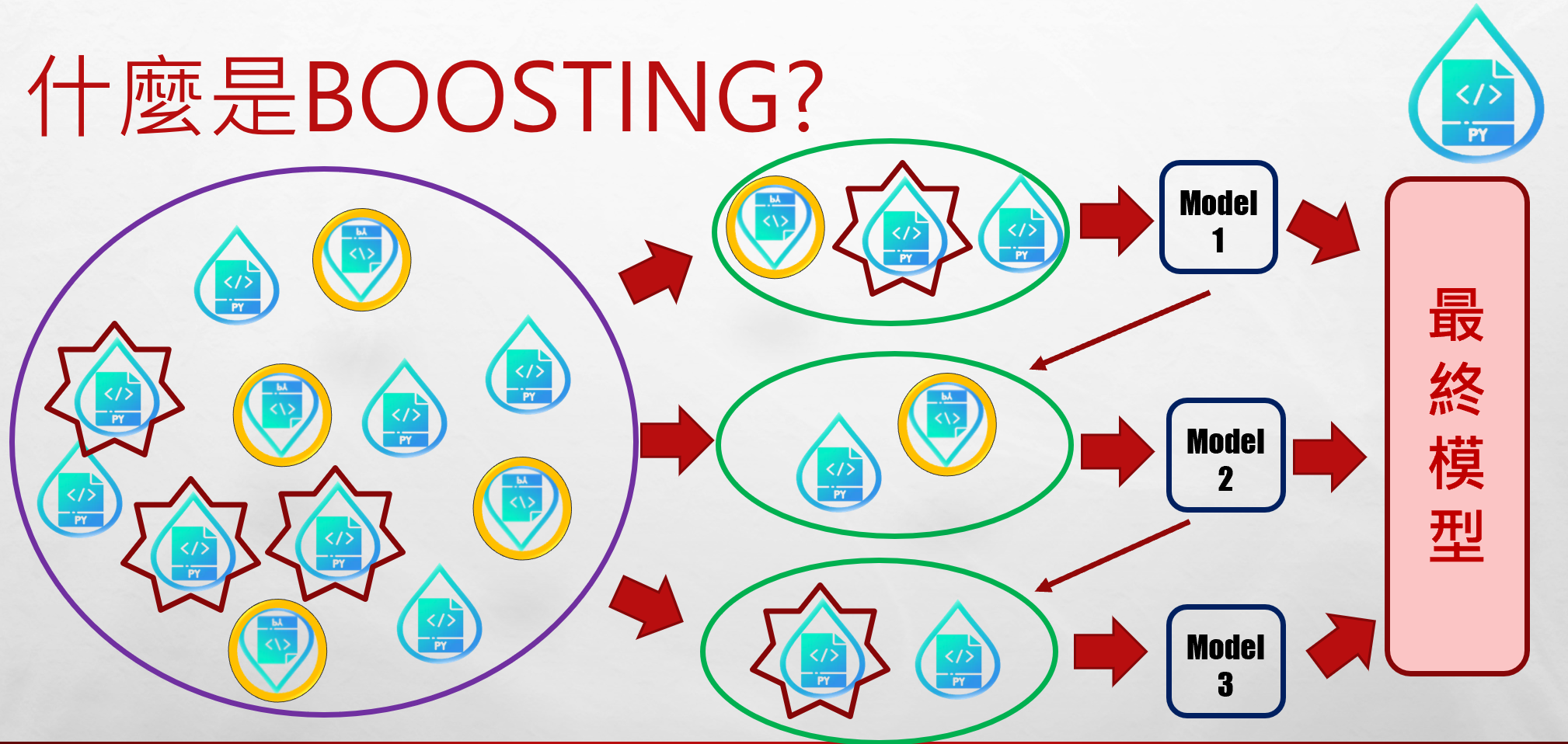
什麼是Boosting?
與Bagging一樣,Boosting同樣會集結多個分類器。然而不同的是,Bagging方法裡的子分類器各自獨立,而Boosting裡的分類器則會由前一個分類器的結果而做更進一步的修正,因此每個分類器皆有所關連。另外,在Bagging裡面,最後的結果是採取民主體制,一人一票,票票等值的方式進行。而在Boosting裡面則是菁英體制,準確度高的給予較高權重。
Boosting背後的演算法
以AdaBoost為例,我們可以看到,假設我們原本的訓練資料集裡面有m筆資料,那麼一開始我們每筆樣本被抽到的機率就是$\frac{1}{m}$。
然後我們會進行$T$輪的迭代學習
在每一次迭代,我們都會根據現在樣本抽到機率使用弱學習器進行學習,進而得到這次迭代的模型,然後再去計算這次迭代模型的誤差,然後更新每個樣本被抽到的機率,然後準備進行下一輪。 其詳細的演算法可觀看下圖

下一輪的$i$樣本抽中機率$D_i^{t+1}$是根據這一輪模型$h_t$的預測誤差$\epsilon_t$來更新,演算法會先根據誤差更新一個權重($w_t$),然後再用權重更新下一輪的抽中機率。
對於這個AdaBoost演算法,背後有下列的理論保證

之後有機會會在統計學習理論的單元進行分享。
Bagging 與 Boosting的主要差異
Bagging
Boosting
樣本抽樣
取後放回,每次抽取都是獨立的
依據前一次模型表現調整
樣本權重
相同
前一次分類錯誤率愈高,則權重愈大
子模型權重
相同
子模型表現錯誤率愈小,權重愈大
平行運算
可以
不可
用途
減小Variance
減小Bias
如何在Python裡運行Boosting?
在這邊,我們一樣採用大家所熟悉的鳶尾花資料集進行演示,完整程式碼歡迎於Github下載。詳細說明詳見影片。
引入套件
在sklearn.ensemble裡面,有著各式各樣已寫好的boosting方法。
from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import GradientBoostingClassifier
下載資料
資料的部分,大家可以採用自己的真實資料,將格式分別整理成特徵及標籤兩個部分即可。在這邊,那我們採用sklearn裡面所提供的鳶尾花資料集。
from sklearn import datasets iris=datasets.load_iris() X=iris.data y=iris.target
區分訓練集與測試集
有了完整的資料以後,我們會將這些樣本區分為訓練集以及測試集。用訓練集的資料來建模,並用測試集資料來驗證結果,以避免過度擬和的問題。
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state=0)
Boosting
在這邊,我們會用兩個方法進行Boosting的演示,分別為Ada Boost與Gradient Boos.
Ada Boost
分類問題可以採用AdaBoostClassifier,連續型問題可以採用AdaBoostRegressor。
adb= AdaBoostClassifier() adb.fit(X_train,y_train) adb.predict(X_test) adb.score(X_test,y_test)
在AdaBoostClassifier裡面,有幾個重要的參數 base_estimator: 子模型 (弱學習器) n_estimators: 子模型數量 learning_rate: 子模型權重縮減係數
Gradient Boost
分類問題可以採用GradientBoostingClassifier,連續型問題可以採用GradientBoostingRegressor。
gb=GradientBoostingClassifier() gb.fit(X_train,y_train) gb.predict(X_test) gb.score(X_test,y_test)
其中,在GradientBoostingClassifier裡面,有幾個重要參數如下: loss: 損失函數 n_estimators: 子模型數量 learning_rate: 子模型縮減係數
今天,我們認識了Ensemble learning裡面的Boosting方法,並學會了如何在Python裡進行實作。拿起你的資料,一起實作看看吧!
參考資料
Understanding Machine Learning: From Theory to Algorithms, Shai Shalev-Shwartz