這個單元,我們以大家所熟悉的鳶尾花分類案例,來看到在Python中如何實作SVM。另外,我們也會以圖像化的方式,帶大家一起看到不同核函數之間的差異!文末提供程式檔案,歡迎大家下載一起練習唷!
(一) 引入模組
除了我們一般常用的模組及資料集外,本單元最重要的是要引入sklearn裡面的svm模組唷!
from sklearn import svm import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split
(二) 準備資料
接下來,我們要準備建立模型所需的樣本資料,並簡單將他們區分為訓練集與測試集,以避免過度擬和的問題。舉例來說,如果我們要看所有上市股票未來3個月會漲還是會跌,我們可以用過去股票漲跌的資料當作目標,並整理一些更過去我們覺得會影響股票漲跌的資料當作我們的特徵(如 股價、成交量、股利、波動度、財報資料、技術指標、籌碼等等),並把一部分的股票當作訓練集,用來建模;另一部分則當作測試集,評斷我們模型的成果。
1.下載練習資料
在這邊,我們採用sklearn所提供的鳶尾花資料集,以花萼及花瓣的長度與寬度為特徵,來預測該鳶尾花是屬於哪一種類的鳶尾花。
iris=datasets.load_iris() X=iris.data y=iris.target
2.將樣本分成訓練集與測試集
接下來,為了避免過度擬和的問題,我們一般來說至少會將樣本區分為訓練集與測試集。sklearn模組裡面提供了很好用的train_test_split功能,能將我們的樣本按照我們所想要的比率區分成訓練集與測試集。以下例來說,test_size=0.2代表的就是測試集佔所有樣本的20%,訓練集則佔所有樣本的80%。而這個功能會幫我們隨機分割,也就是說同樣的程式碼每次執行時,雖然每次都是以測試集20%,訓練集80%在做分割,但其實每次分割的內容都不太一樣。因此,如果未來我們要優化模型重跑程式碼時,訓練集與測試集的樣本也會有所不同,進而帶來不同的結果。為了避免這樣的狀況,我們也可以以設定random_state的方式來固定種子,設定後不論跑多少次,分割的內容都會相同了!
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2,random_state=0)
(三) 建立模型
當我們準備好資料後,模型的建立也非常簡單,因為sklearn裡面的模組通通幫我們寫好了,我們只要學會怎麼使用就好。
第一步當然就是選擇模型,在這個鳶尾花分類的例子裡,我們所選擇的是svm裡面的SVC分類器,括號裡面的參數分別代表著核函數的選擇、懲罰係數大小以及支援向量機的多寡,後續我們會再做介紹。第二步則是讓選擇好的模型fit我們的資料,這樣,就完成了!
clf=svm.SVC(kernel='rbf',C=1,gamma='auto') clf.fit(X_train,y_train)
在這邊,我們也來分享3個svm模型裡面的主要參數。當然不只這三個可以調整,對其他參數有興趣的朋友歡迎詳閱官網文件。
1. 核函數 kernel
在模型裡面,我們可以選擇各式各樣的核函數,包含線性、多項式、高斯、sigmoid等等,也可以自訂,以符合資料的需求。
為了視覺化,在這邊我們僅選取花瓣的長度及寬度當作特徵,讓各位讀者感受看看不同核函數之間的差異。
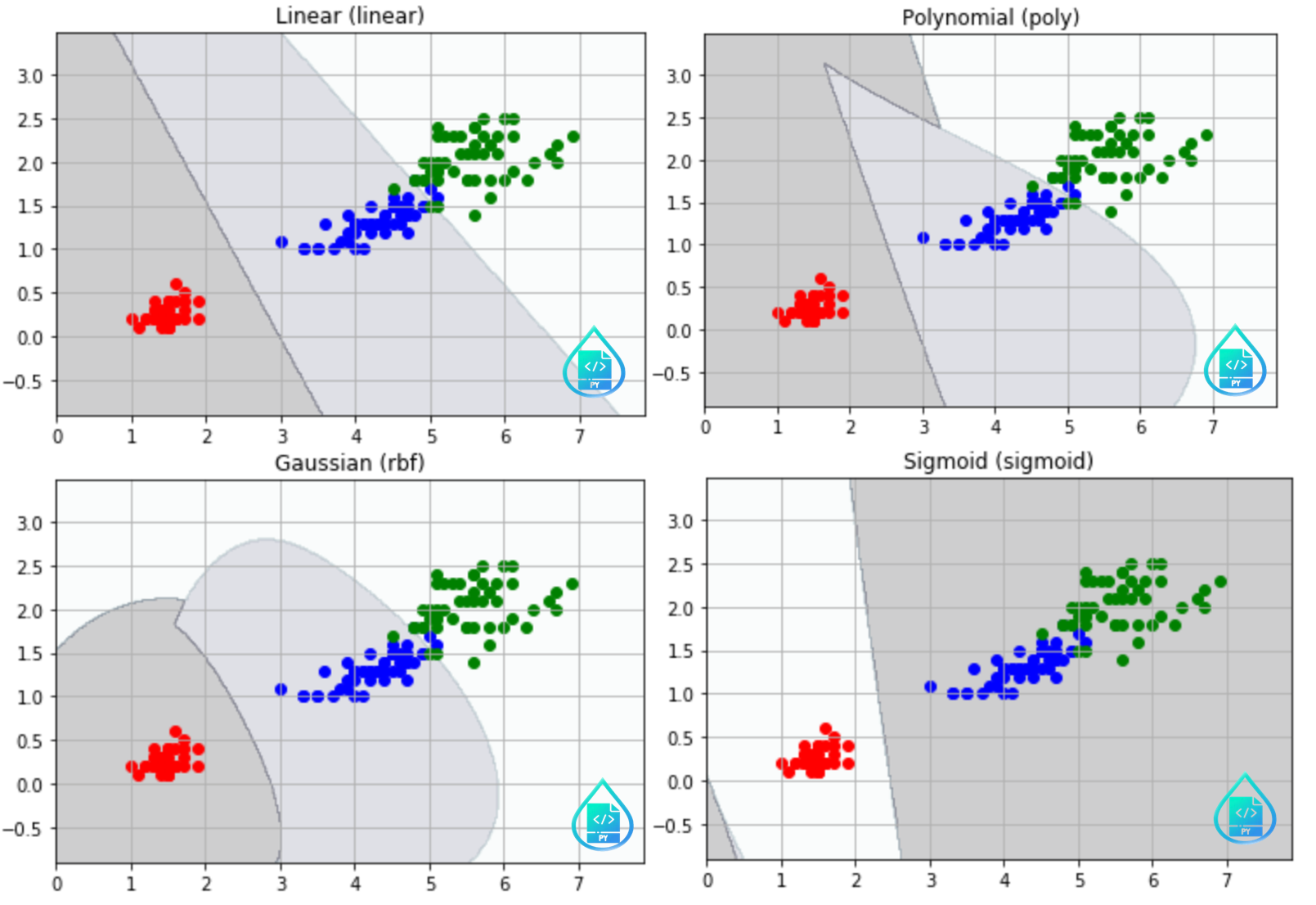
2. 參數C
C為懲罰係數。 C愈大代表錯誤的容忍程度愈低,在訓練集樣本中會區分的愈精細,因此設定太大容易造成過度擬和的問題。反之,設定太小則會造成低度擬合的問題。若沒設定,模型中預設為1。
3. 參數gamma
gamma參數決定支援向量的多寡,並影響訓練速度與預測速度 。此參數有兩個自動運算選擇,分別為’scale’與’auto’,或是也可以直接指定數值,設定後會以下列方式算出隱含參數,以決定資料映射到新特徵空間後的分佈,在未設定下預設為’scale’。
gamma=’scale’: $gamma值=\frac{1}{(n_{features} \times X.var())}$
gamma=’auto’: $gamma值=\frac{1}{n_{features}}$
4. 其他補充
順帶一提,因為我們要做的是類別分類(三種類型的鳶尾花),並且可以選擇各種不同的核函數,所以我們這邊採用的是svm.SVC (Support Vector Classification)。如果是連續型的資料,可以採用svm.SVR(Support Vector Regression)。比較仔細的讀者可能會發現影片中我們還有採用svm.LinearSVC (Linear Support Vector Classification),這個也是線性的,但其中的演算法跟我們採用svm.SVC(kernel=’linear’)是不一樣的,所以結果也會不一樣,詳細差異可以閱讀官網的官方文件。一般來說,在樣本非常龐大時,用svm.LinearSVC的運算速度會比較快,而針對連續型資料同樣可以採用svm.LinearSVR (Linear Support Vector Regression)。
(四) 預測
模型建置都完成後,我們就可以開始對我們的測試集進行預測啦! 一樣,我們用模型.predict(測試集特徵),就可以預測出這些測試集樣本所對應到的鳶尾花種類了!
clf.predict(X_test)

(五) 準確度分析
在這裡,我們一樣用 模型.score(特徵, 目標),來檢視我們的模型再訓練集以及測試集的精準程度。
print(clf.score(X_train,y_train)) print(clf.score(X_test, y_test))

今天,我們學會了如何在Python中實作SVM模型,並看到各種核函數的變化差異。邀請你用自己的資料試驗看看,找到適合的核函數,建立自己的預測模型! 多多練習,熟能生巧,讓我們一起把機器學習融入生活!
程式檔案,請按此下載。