邏輯斯迴歸模型是處理二元分類相當好用的模型。上個單元,我們已經認識了邏輯斯迴歸模型。本單元,在影片中我們透過兩個大家熟悉的小例子,用Python來實作二元的邏輯斯迴歸與多元的邏輯斯回歸。歡迎大家跟著一起練習,或是下載程式檔案一起操作。以下幫大家紀錄實作重點。
(一) 前置作業
在python裡,最棒的事情就是有很多專家已經寫好的模組,包含機器學習的部分!因此,實作中我們都會先引入這些模組來使用。另外,在機器學習中為了避免過度配適,抽取部分樣本建模也是很重要的一環。在此,我們僅採用最基本的簡單將資料區分為訓練及與測試集。
1.模組引入
本單元邏輯斯迴歸的模型就在sklearn模組裡面的linear_model底下,因此使用前我們需要先引入這個模組。(其他模組的介紹歡迎參考我們的基礎單元。)
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import linear_model
2.訓練集與測試集區分
from sklearn.cross_validation import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
區分訓練集與測試集中,我們可以引入sklearn.cross_validation裡面的 train_test_split,他可以協助我們自動將樣本隨機分為訓練集與測試集。如同上面程式碼第二行,我們可以透過test_size來決定測試集的比例。
(二)模型
1.模型建構
第一步,我們可以透過sklearn模組裡面linear_model底下的LogisticRegression()來建構我們的模型,而括號中可以依需求調整各式各樣的參數以優化模型,詳細參數調整可參考官網。第二步,讓模型fit我們的訓練集資料。到此,我們的模型已經建構完成了!
model=linear_model.LogisticRegression() model.fit(X_train,y_train)
值得一提的是,我們都知道邏輯斯迴歸分類器為一種二元分類器。那多元分類可以用邏輯斯回歸嗎? 答案是可以的! 怎麼做呢? 其實,我們可以把多個邏輯斯迴歸模型組合在一起,就變成多元邏輯斯分類器囉! 更棒的是,在我們現在採用的模組中,程式已經準備好這個部份了! 因此,我只管把模型fit我們的資料,剩下的通通交給程式自動處理!
2.模型預測
接下來,我們可以餵入測試集的資料,用predict來看該樣本相對應的預測結果。
model.predict(X_test)
另外,在邏輯斯迴歸簡介單元中我們提過,邏輯斯迴歸分類模型為一種二元分類器。其原理為對勝算比取對數作迴歸後,再透過Sigmoid函數轉換,將結果對應到相對的事件發生機率。若機率大於0.5代表事件發生機率相對高,則回傳1 ; 若機率<0.5代表事件發生機率相對低,則回傳0。因此,我們也可以透過predict_prob來看到該樣本在各個類別事件發生的機率。
model.predict_proba(X_test)
3.預測結果
最後,我們同樣可以透過score,經由對答案的方式來看我們模型在訓練集或測試集判斷成功的比重。如果在訓練及分數很高,但是在測試及分數很低,則代表模型有可能過度配適了,那就需要重新修正!
model.score(X_test,y_test)
(三)多元邏輯斯迴歸分類概念
在模型建構的部分我們提到,只要將多個邏輯斯迴歸分類器結合在一起,就可以變成一個多元分類器囉! 這個部分是怎麼運作的呢?
以影片裡鳶尾花的例子來說,我們有三種鳶尾花,但邏輯斯迴歸分類器一次只能分兩種! 因此,我們可以重複同樣動作三次,先把第一種鳶尾花獨立出來,第二種跟第三種視為同一種。第二次時,再把第二種鳶尾花獨立出來,並將第一種跟第三種視為同一種。第三次時,將第三種鳶尾花獨立出來,並把第一種與第二種視為同一種。最後,再將這三個模型結合在一起,就知道每個樣本在哪一個類別的機率最高,就可以輸出最後的成果囉! (如下圖)
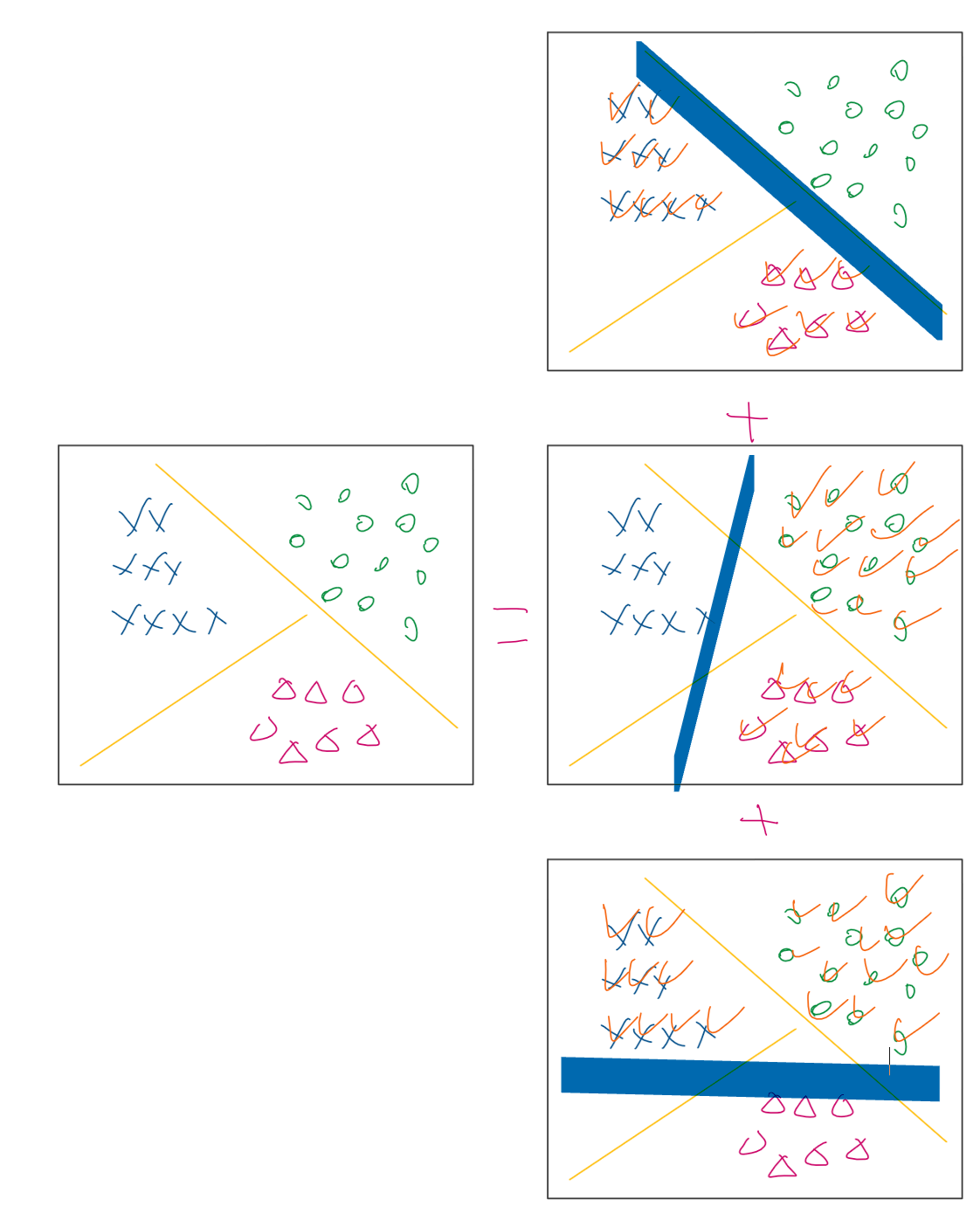
綜合以上,我們已經學會了如何在python實作邏輯斯迴歸,以及多元邏輯斯迴歸的概念! 下個單元,我們將進入貝氏分類器囉!
歡迎下載本單元程式檔案,按此下載。